El Código Kerry
Hace muy poco tiempo cayó en mis manos el código fuente de un proyecto experimental. Este código me resultó muy útil para un proyecto propio que me traía entre manos. No obstante, la calidad del código original era pésima. Me costó trabajo entender lo que sucedía en ese proyecto: primero pensé que el autor había tenido alguna poderosa razón para haber montado aquel desastre que tenía ante mí. Sólo cuando me di cuenta de que no había "nada más", pude pasar a la acción y aprovechar las partes útiles, con la ayuda de una buena tijera y mucha paciencia. Curiosamente, la mayoría de los fallos en el diseño seguían un claro patrón, y esta contumacia en el error me animó a escribir este pequeño artículo.
Reconozco que no es justo criticar el código de un proyecto que te ha sido útil, por lo que voy a disfrazar los ejemplos, adaptándolos al diseño del compilador de Freya. He llamado "código Kerry" a estos defectos de programación en homenaje a John Kerry, político famoso por tener dos puntos de vistas opuestos para cada cuestión, y en usar siempre el que más le gustaba al interlocutor de turno. Como decía Marx (Groucho, por supuesto):
"Estos son mis principios. Si no le gustan, no importa: tengo otros..."
UN MAL TRUEQUE
Comencemos por el primer disparate. Imagine que la declaración de un método contiene una lista de objetos derivados de la clase abstracta Instrucción. La parte más importante del algoritmo que genera el código ejecutable del método sería parecida a esto:
foreach (Instrucción instr in Instrucciones)
instr.Generar(generador);
Caso típico en la P.O.O., diría uno, ¿no? Una lista polimórfica, en la que puedes encontrar objetos variopintos. Todos ellos, sin embargo, implementan un método virtual llamado Generar, que se ocupará de los detalles particulares adecuados a cada caso. En efecto, si vamos a la clase base Instrucción nos encontramos con esta declaración:
public abstract class Instrucción
{
public abstract void Generar(Generador generador);
// ...
}
Hasta aquí, todo muy correcto. El susto me lo llevé cuando vi lo que se había programado en las implementaciones de Generar de cada clase:
public class Asignación
{
public override void Generar(Generador generador)
{
generador.Generar(this);
}
// ...
}
En esto punto, ya temía lo peor, y la confirmación llegó al buscar en la clase Generador qué demonios hacía este misterioso Generar:
 public class Generador
{
public void Generar(Asignación instrucción)
{
// Generación de código para asignaciones.
}
public void Generar(InstrucciónIF instrucción)
{
// Generación de código para condicionales.
}
// Repetir hasta el infinito y más allá...
} public class Generador
{
public void Generar(Asignación instrucción)
{
// Generación de código para asignaciones.
}
public void Generar(InstrucciónIF instrucción)
{
// Generación de código para condicionales.
}
// Repetir hasta el infinito y más allá...
}
Este tipo de movimiento mareante recibe un nombre en inglés: la onomatopeya flip-flop. También se usa este nombre para las chanclas del tipo que aparecen en la imagen, por el ruido característico que hacen. Y el código mostrado es un claro ejemplo de flip-flop absurdo: saltamos de una clase a otra, y como veremos enseguida, estos saltos no es que no tengan sentido. ¡Es que son altamente nocivos!
Lo malo de esta "técnica", por llamarla de algún modo, es que se apoya en un recurso muy potente (la llamada polimórfica basada en el late-binding) para hacer que funcione un recurso patatero: la sobrecarga de métodos en tiempo de compilación. Comencemos, no obstante, por lo positivo. En realidad, lo que hay detrás de cualquier algoritmo de este tipo es un bucle con un gran switch o case en su interior:
foreach (Instrucción instr in Instrucciones)
if (instr is Asignación)
instr.Generar(generador);
else if (instr is InstrucciónIF)
instr.Generar(generador)
else
// ...
Al menos, el perpetrador del código Kerry nos ha ahorrado el gigantesco selector de casos. En vez de discriminar casos explícitamente, el autor ha utilizado una llamada a un método virtual. El mecanismo de llamada nos asegura que se ejecutará la versión de Generar definida para la clase concreta que tengamos entre manos. Ese primer paso está bien dado. ¿Por qué es tan "grave" lo que pasa a continuación?
Lo que se dinamita es el cimiento de todo el edificio de la P.O.O.: el criterio utilizado para la descomposición modular. ¿Cómo funciona un compilador? ¿Qué hace? Para simplificar, nos centraremos en dos operaciones que debe llevar a cabo: la resolución de símbolos y la generación de código. He escogido la primera de ella al azar: en dicha fase, cada vez que encontramos un identificador, intentamos averiguar de qué se trata. Puede ser un nombre de clase, o un espacio de nombres, o un campo de una clase, o una variable local... Se pueden hacer muchas cosas en esa fase, pero para simplificar lo dejaremos así. Y no creo necesario explicar qué hace la generación de código.
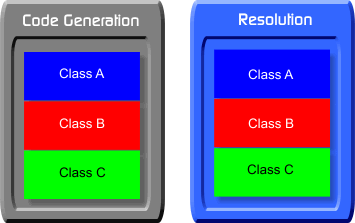
En las metodologías anteriores a la P.O.O., el diseñador de la aplicación partía de las operaciones que debía ejecutar el programa para dividir el código fuente en partes manejables. En el caso del compilador, la división podía adoptar la siguiente fórmula:
Observe que en el nivel superior del diseño, hemos dividido el código en dos módulos. El código de generación, a un lado; el de resolución, en el otro. Sin embargo, dentro de las tareas de la generación hay que volver a dividir el código fuente. En el diagrama, dentro de cada módulo hay tres subdivisiones identificadas arbitrariamente como clases A, B y C. Para concretar, puede imaginar que la clase A se ocupa de las asignaciones, la B de las condicionales y la C de los bucles. Esa misma subdivisión se repite en el otro módulo.
En primer lugar, ¿se ha dado cuenta de que el código Kerry está basado en esa metodología prehistórica? Físicamente (este adverbio es muy importante), todo el código fuente relacionado con la generación de código ha quedado agrupado, probablemente en un fichero o en un pequeño grupo de ellos. Lo mismo ocurre con el módulo de resolución. Lamentablemente, el código fuente es una estructura lineal, y si lo dividimos de acuerdo a los módulos de funcionalidad, no podemos dividir a la vez por entidades; en todo caso, podemos subdividir. ¿El resultado? Pues que para comprender cómo el compilador maneja una instrucción de asignación tenemos que realizar una lectura transversal.
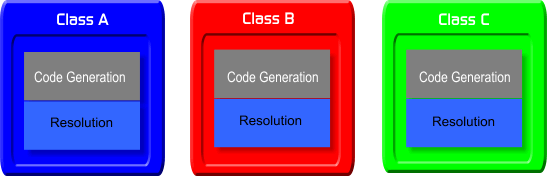
¿Es eso malo o bueno? Hay que ver primero cuál es la alternativa. La P.O.O. aboga por la descomposición modular basada en los objetos, no en la funcionalidad. Esta es la alternativa:
El razonamientos simétrico es válido, por supuesto: bajo estas premisas, para entender cómo funciona una operación, tendremos ahora que realizar la temida lectura transversal. Por lo tanto, tenemos que elegir:
- Hacemos que sea sencillo leer, comprender y actualizar el código de toda una operación, haciendo difícil la agrupación de código basadas en la taxonomía.
- Hacemos que sea sencillo leer, comprender y actualizar el código asociado a una entidad, haciendo difícil la agrupación del código correspondiente a cada tarea.
Ahora romperemos la aparente simetría con una inocente pregunta:
¿Qué será más frecuente: que añadamos operaciones o que añadamos objetos?
No sé si habrá una respuesta unívoca y necesaria a la pregunta anterior. Mi experiencia me dice que es más frecuente que añadamos nuevos tipos de entidades a un sistema ya existente. Mientras esto sea cierto, y todo el mundo parece estar de acuerdo en ello, es preferible la división modular guiada por la clasificación en entidades. Es decir, todo lo contrario a la programación "estilo Kerry".
 |
|
No puedo resistirme, sin embargo, a señalar con sorna un problema de la descomposición modular basada en objetos. ¿Cómo se comporta el código dividido de esta manera en una CPU "moderna"? Como es fácil de comprender, el puntero a la instrucción activa va a saltar incesantemente de una clase a la siguiente. Pero todas las CPUs modernas dependen en gran medida de una caché interna de código para la ejecución óptima, y este paseo frenético a lo ancho y largo del segmento de código no es precisamente positivo para la velocidad del ordenador. ¿Soluciones? Hay pocas, y todas son complicadas de implementar. La más prometedora es (¡qué casualidad!) el uso de sistemas inteligentes de carga, como el de .NET, que sean capaces de reubicar el código ejecutable proveniente de ensamblados diferentes de modo que los fragmentos de funcionalidad relacionada se sitúen en zonas cercanas. Sinceramente, no sé si el cargador de .NET ya se ocupa de este problema, pero va a tener que hacerlo más temprano que tarde, sobre todo porque la arquitectura de 64 bits de Intel depende mucho de la inteligencia del compilador para lograr velocidades aceptables (el procesador de 64 bits de AMD es mucho más robusto y tolerante, en este sentido).
|
¿Cómo quedaría el código una vez depurado de estas marranadas? Muy simple: el código concreto de la generación de instrucciones se mueve a cada una de las implementaciones del método Generar, introducido por la clase abstracta Instrucción. El papel de la clase Generador disminuye en importancia, y sólo proporciona almacenamiento para el estado global del algoritmo, a la vez que ofrece algunos servicios auxiliares para la generación.
RENDICION PREVENTIVA
Si el código de aquel proyecto sólo hubiese contenido este tipo de error, no me habría venido a la mente la imagen del flip-flop. Para mi desgracia, el diseño tenía otro fallo importante, y esta vez era más difícil corregirlo. El efecto neto en el código también parecía ser un insensato flip-flop, pero las razones eran diferentes. La explicación es también más complicada, al no poder usar el ejemplo original y tener que adaptarlo al compilador de Freya. De modo que no espere una moraleja clara, sino orientaciones generales y algunas reglas de higiene.
Suponga que estamos programando ya la fase de resolución. En concreto, estamos analizando los distintos tipos de expresiones. Durante la fase de análisis sintáctico desconocemos que PI es una constante y que Math es un nombre clase. A priori, una cadena de identificadores como System.Math.PI podría interpretarse como un espacio de nombre (toda ella), como un espacio de nombre seguido del nombre de la clase PI... o la interpretación correcta: un espacio de nombre, seguido por un nombre de clase, seguido de una constante simbólica. Por eso, el analizador sintáctico crea expresiones de clases basadas solamente en la estructura textual, como SimpleExpr, DotExpr, BracketExpr... La expresión de corchetes, por ejemplo, podría significar un acceso a un elemento de un vector o el acceso una propiedad indexada.
Una de las operaciones de la fase de resolución es la que permite "profundizar" en una cadena de identificadores. Suponga que ya sabemos que System.Math se refiere a una clase. Ahora tenemos que seguir "profundizando", porque nos encontramos con el identificador Sqrt: System.Math.Sqrt. ¿Qué significa la nueva cadena de identificadores? ¿Cómo organizamos el algoritmo que averigua estas cosas?
Hay dos elementos que deciden el algoritmo adecuado para cada caso:
- La expresión de partida: si partimos de System.Math, es decir, de una clase, tendremos que buscar el nuevo identificador entre los miembros directos de la clase. Si la búsqueda falla, hay que buscar en la clase base, si existe. Si partimos de una expresión que representa un espacio de nombres, sabemos a ciencia cierta que el nuevo identificador corresponderá a un tipo o a un espacio de nombre anidado.
- Una vez que sabemos qué significa el nuevo identificador, de acuerdo al contexto, hay que decir qué haremos con él: si crearemos una referencia a un campo, o una referencia a una clase, o una referencia a un espacio de nombres. En cada uno de estos casos, las comprobaciones semánticas dependerán del tipo de entidad representado por el identificador recién añadido a la ruta.
Como puede ver, en el caso general podríamos encontrarnos con una matriz de decisión bidimensional. El error al que me refiero en esta sección consiste en programar esta operación bajo el siguiente esquema:
public class SymbolExpr : Expression
{
public override Expression DrillDown(string identifier)
{
Symbol newSymbol = this.symbol.Scope.DrillDown(identifier);
if (newSymbol is MemberSymbol)
// primer caso...
else if (newSymbol is TypeSymbol)
// segundo caso...
else if (newSymbol is ConstantSymbol)
// tercer caso...
// ...
}
}
Ya estamos ahorrándonos el consabido y pecaminoso selector de casos basado en el tipo de entidad: estamos aplicando la técnica ortodoxa de definir un método virtual y dejar que el mecanismo de llamadas polimórficas siga su curso habitual. Sin embargo, una vez dentro del método activado, ¡volvemos a toparnos con un maldito selector de casos! Este patrón se repetía constantemente a lo largo del proyecto de mis desdichas.
Espero que haya identificado el error con facilidad: esos selectores son una pesadilla y complican la comprensión y el mantenimiento del código. Además, es muy fácil saltarse casos por descuido... y descubrirlo, si hay suerte, al ejecutar el proyecto con una batería exhaustiva de pruebas. Sin embargo, el diagnóstico no trae, esta vez, aparejada la solución. O tal vez sí: está claro que tenemos que aplicar las técnicas de P.O.O. hasta el final. Lo difícil es tener la paciencia necesaria y los redaños para no rendirse antes de plantar batalla.
¿Qué deberíamos hacer? Mi compilador, en el caso anterior, define un método virtual en la clase base Symbol, y simplifica ese código de esta forma:
public class SymbolExpr : Expression
{
public override Expression DrillDown(string identifier)
{
Symbol newSymbol = this.symbol.Scope.DrillDown(identifier);
return newSymbol.ComposeObjectPath(this);
}
}
¡Esta vez hemos añadido el flip-flop con toda intención! Primero, la llamada a DrillDown, introducido por la clase Expression, selecciona un elemento de una de las dimensiones de la matriz de casos. Luego, para seleccionar en la otra dimensión, pasamos la pelota a ComposeObjectPath, de Symbol. ¿Por qué este flip-flop cuenta con mis bendiciones y el otro no? Está claro: en ambos saltos, aprovechamos la llamada polimórfica para elegir la acción apropiada, algo que no se cumplía en el ejemplo anterior.
No hay soluciones mágicas, excepto el esfuerzo constante, pero prometí algunas reglas higiénicas. Ahí van:
- No hay nada malo en saltar de clase en clase, si la situación lo requiere. Lo que es un error es utilizar el mecanismo con fines espurios, como calzar una resolución estática, en tiempo de compilación.
- Ante la duda, compruebe si el código asociado a una entidad está alojado de forma contigua con el resto del código de la entidad. Si para entender cómo funciona una entidad hay que ir dando saltos de fichero en fichero, nos hemos apartado del Tao en algún momento.
- ¡No se rinda antes de plantar cara!Hay quien piensa, cuando tiene que realizar una segunda llamada polimórfica encadenada, que no puede estar bien lo que está haciendo. Amigo mío, bienvenido a la vida real. Pocas veces un libro de programación tiene la posibilidad de mostrar ejemplos realmente complejos, pero estos abundan, por supuesto.
Una advertencia: el algoritmo del ejemplo que he seleccionado es un algoritmo "separable". La definición formal de separabilidad es algo compleja, pero creo que entenderá la idea. A veces, no es posible separar claramente los casos mediante llamadas polimórficas sucesivas. Si tropieza con uno de estos casos patológicos, pruebe, antes de complicar definitivamente su código fuente, con algún modelo de objetos alternativo. Muchas veces los enmarañamientos de este tipo se debe a una mala elección inicial de las entidades del sistema.
PENSAMIENTOS EN VOZ ALTA
No sé si se habrá dado cuenta de que la mayoría de nuestros males surgen del carácter lineal de la representación del código fuente. Cualquier división del código puede separar fragmentos algorítmicos relacionados según algún criterio útil. En la base de la P.O.O. encontramos la decisión de favorecer un tipo de descomposición modular, basándonos en una serie de consideraciones sobre qué es lo más útil y frecuente. ¿Sería posible que existiesen otras soluciones para estas dificultades?
Es fácil divisar alternativas. Para empezar, ¿por qué nuestro código fuente debe ser necesariamente lineal? Por ejemplo, ¿es lineal un hipertexto? La Programación Orientada a Aspectos tiene también mucho que decir en estos problemas. Es complicado todavía, en esta etapa de su evolución, separar el grano de la paja, pero hay señales prometedoras en el horizonte.
Ah, por cierto... no sea excesivamente duro con el señor Kerry. Es verdad que es malo oscilar constantemente entre dos posiciones opuestas. Pero es mucho peor no tener ninguna posición... o esconder una inconfesable.
|