 |
 |
|

|
Novedades en el acceso a datos con VS2008LA OPCIÓN DATASET PROJECT¡Por fin! Cuando aparecieron los table adapters, en Visual Studio 2005, me quejé porque no eran apropiados para trabajar en tres capas. En efecto, aunque se puede definir un conjunto de datos con tipos (typed dataset) sin tener que cargar con un adaptador, lo contrario es imposible: todo adaptador tiene su dataset adosado.
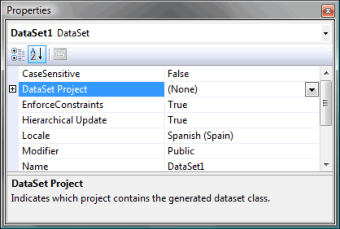
Todo esto ha mejorado mucho en VS2008: ahora, al diseñar un table adapter, se puede pedir que las clases correspondientes al conjunto de datos y sus tablas se generen dentro de un segundo proyecto. Una aplicación sencilla en tres capas puede implementarse ahora como una solución con tres proyectos: un proyecto de tipo Class Library, que contendrá los conjuntos de datos y será utilizado por los otros dos proyectos, un proyecto para la capa intermedia, y el proyecto ejecutable con la capa de presentación. En circunstancias reales, la capa intermedia suele dividirse en dos partes, como mínimo: una biblioteca de clases con los adaptadores de tablas y otros componentes conectados, y el proyecto host que debe albergarlo. Este último puede ser una aplicación de servicio, o un servicio Web de ASP.NET, o lo que se le ocurra. Ahora es posible utilizar table adapters en serio, simplificando mucho la programación de las actualizaciones. Tenga presente, no obstante, que una aplicación decente seguirá utilizando componentes "proscritos" como SqlDataAdapter: los adaptadores de tablas sólo trabajan con una consulta, mientras que la lectura eficiente de relaciones maestro/detalles debe realizarse agrupando consultas en un mismo comando. ¿Cómo? :) En el curso lo explico... TABLE ADAPTER MANAGERDe todos modos, los adaptadores de tablas deben usarse para las actualizaciones, y ahora con más motivos que antes: Visual Studio 2008 genera, para conjuntos de datos con relaciones maestro/detalles, una clase especial que coordina el orden de las grabaciones. La clase se genera cuando la opción Hierarchical Updates del conjunto de datos está activa. ¿Tiene usted que grabar modificaciones en facturas y líneas de detalles? Entonces tiene que enviar las modificaciones a la base de datos en un mínimo de tres grupos: primero, las inserciones y modificaciones en cabeceras, luego todos los cambios en detalles, y finalmente, los borrados de cabeceras (asumiendo que estos no generan una cascada de borrados en la base de datos). Antes, había que programar cuidadosamente esta división de los registros en grupos. Ahora lo hace una clase generada por cada conjunto de datos. INICIALIZACIÓN EN CONJUNTOS DE DATOS CON TIPOSEste es un cambio relativamente pequeño, pero importante. A diferencia de C#, VB.NET permite declarar un manejador de eventos y engancharlo declarativamente al evento en cuestión. ¿Consecuencias? Cuando usted diseña un conjunto de datos con tipos en un proyecto VB.NET y hace doble click sobre una columna, el diseñador crea automáticamente un manejador para el evento ColumnChanging de la tabla... y lo inicializa, enganchándolo al evento. Esto no puede hacerse en C#. Es verdad que siempre nos queda la posibilidad de reescribir el método virtual protegido OnColumnChanging, pero cuando se trata del evento RowChanging y su familia, tal posibilidad ya no existe, pues el código generado por Visual Studio ya lo utiliza. En principio, esto se ha resuelto añadiendo métodos parciales al lenguaje, pero esta técnica exige colaboración por parte de la herramienta de generación de código, y el diseñador de conjuntos de datos ha decidido no colaborar (sí se utiliza en LINQ for SQL). Lo que ocurre es que ahora se ha hecho "oficial" la técnica correcta para inicializar estos manejadores de eventos: reescriba el método virtual protegido EndInit, para enganchar todos los manejadores de eventos que se le ocurra. Debo aclarar que esta posibilidad ya existía en VS2005... pero no había sido bendecida con el status de técnica apropiada: usted la podía usar arriesgándose a que, en la siguiente versión de Visual Studio, a alguien en Microsoft se le ocurriese utilizar EndInit con fines particulares. LINQ... oh, no, ¿cómo iba a olvidarme de LINQ, con el revuelo que ha montado? Mi obligación, sin embargo, es darle una idea real sobre el estado actual de su implementación. Y la verdad, como casi siempre, consiste en una mezcla de malas y buenas noticias. La buena noticia: ya puede usar una de las "facetas" de LINQ, llamada LINQ for SQL para programar... con SQL Server. Ahí ya tiene una mala noticia implícita: de momento, sólo funciona con SQL Server. Se supone que uno de los atractivos de sustituir los datasets por listas de objetos está en la mayor independencia respecto al modelo del servidor. Objetivo incumplido, aunque sólo de momento. Otra buena noticia: puede utilizar otra variante de LINQ, el llamado LINQ for Datasets como mecanismo muchísimo más potente de filtro y combinación en conjuntos de datos. Y naturalmente, existe un LINQ para XML, y un LINQ para objetos acechando al hipotético idiota que intente sustituir un simple bucle por una consulta basada en delegados... Ahora las malas:
Incluso si se cumple este requisito, a usted le toca trabajar más. Para que el sistema de actualizaciones funciones, LINQ for SQL obliga a los objetos a existir dentro de un contexto de datos. Al serializar un objeto para enviarlo a la capa de presentación, éste se tiene que desconectar de su contexto. Si el usuario final realiza cambios y reenvía el objeto a la capa intermedia, hay que volver a engancharlo en un contexto... pues el original es más que probable que ya no exista. En cualquier caso, el objeto habrá perdido todo enlace con sus valores originales. De ahí la necesidad de una columna timestamp para el control de concurrencia. E incluso entonces, queda por delante lo más difícil: la reconciliación de errores de grabación y la sincronización del estado de las copias locales en la capa de presentación. Todo eso, hay que hacerlo a mano. No es imposible, claro, pero ¿qué ventajas ha ganado usted con el cambio? ¿Listas de objetos en vez de conjuntos de datos con tipos? No todo lo que brilla es oro: |












 La capa de presentación, sin embargo, es el principal consumidor de conjuntos de datos con tipos, y si utilizamos el mecanismo de generación de Visual Studio, esta capa también tendrá conocimiento de los table adapters. Eso, por supuesto, es un signo de muy mal diseño en sistemas divididos en capas: se supone que la capa de presentación debe aislarse todo lo posible de la capa de acceso al servidor de datos. Para solucionar este problema había que recurrir a las tijeras... o resignarse a publicar la capa intermedia como un servicio Web, dejando que la capa de presentación dedujese el formato de los conjuntos de datos al generar el proxy de acceso al servicio.
La capa de presentación, sin embargo, es el principal consumidor de conjuntos de datos con tipos, y si utilizamos el mecanismo de generación de Visual Studio, esta capa también tendrá conocimiento de los table adapters. Eso, por supuesto, es un signo de muy mal diseño en sistemas divididos en capas: se supone que la capa de presentación debe aislarse todo lo posible de la capa de acceso al servidor de datos. Para solucionar este problema había que recurrir a las tijeras... o resignarse a publicar la capa intermedia como un servicio Web, dejando que la capa de presentación dedujese el formato de los conjuntos de datos al generar el proxy de acceso al servicio.